Avoid dual writes with sql server and change tracking - Part 1
Problem: Consistent updates to multiple data stores
A common problem in web applications is the need to persist updates to multiple data stores (sql, cache, search, etc). Rarely does an application deal only with one data store. How do we get one update from the application into all data stores? The most common approach is dual writes where the application simply writes to each data store in parallel or serial order. This is compelling because it’s easy to implement and works well with low traffic, low error scenarios.
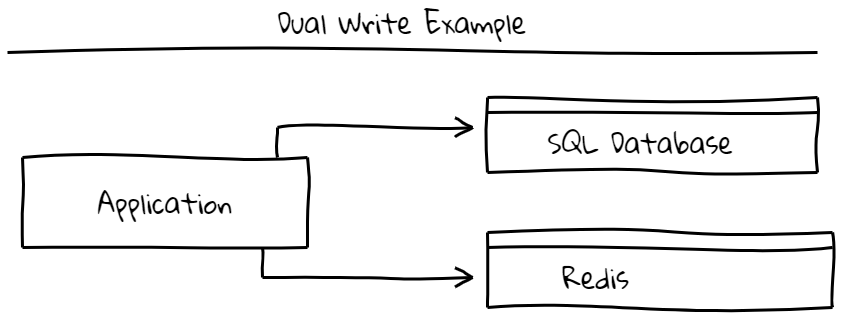
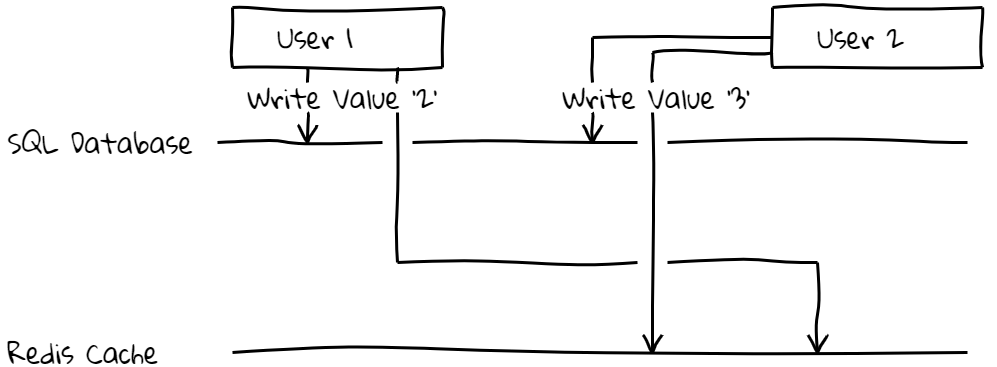
However, there are many tricky errors that can arise. The most common being a failure of one of the writes. One data store has the new data and one has stale data. Another problem is race conditions among the different data store updates like in the diagram below. In this example, the value will be ‘2’ in the SQL database and ‘3’ in the Redis cache. No errors were thrown in this case making it even harder to track down.
How do we deal with these problems? One approach is to build a process to monitor the databases, look for drift between the two, then correct the one that’s out of line. However, this is difficult because you have to infer which database is correct. It’s also slow to analyze the whole database so the difference between the two databases may be “in the wild” for some time.
A better solution is the unified log pattern. At a high level, the unified log pattern is implemented by persisting all writes to one stream data store like Kafka or Azure Event Hubs. The log is consumed by one or more applications that persist the updates to dependent data stores as shown below.
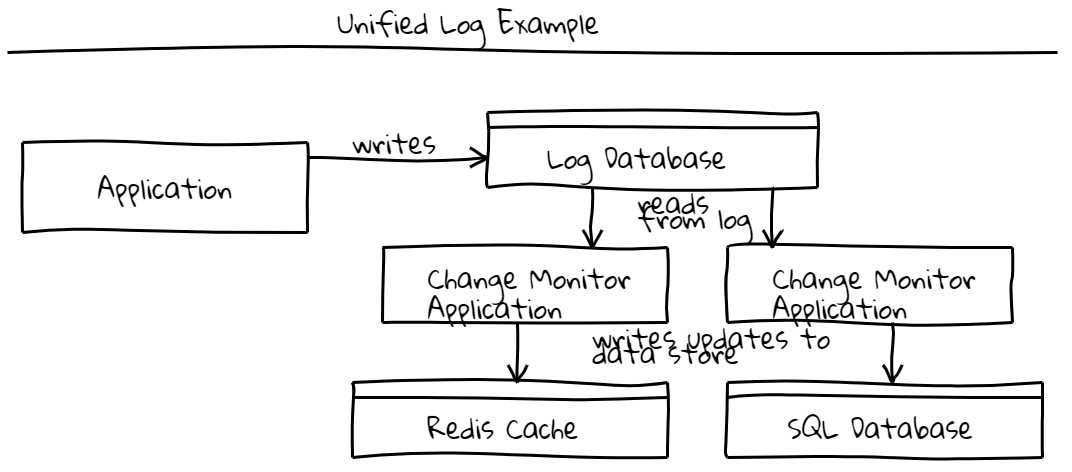
This avoids many of the problems from the dual write scenario but it is difficult to introduce into existing systems that currently write to more traditional data stores like SQL. Additionally, if your team is used to working with traditional databases, a log data store can be a difficult mindset shift.
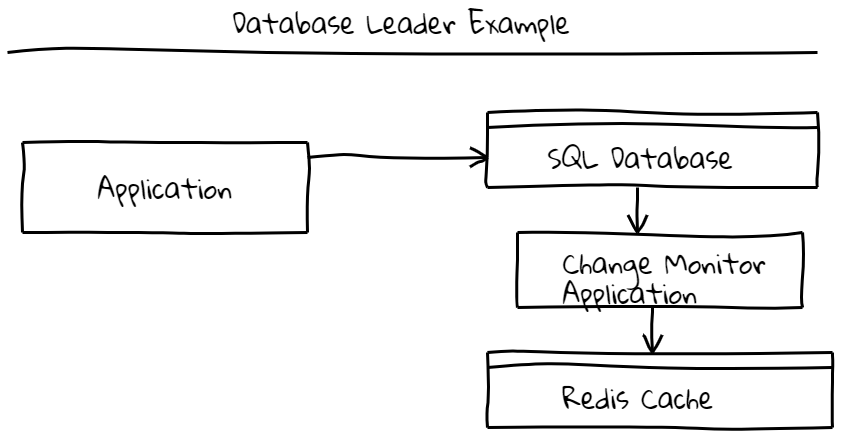
What else can we do? A better solution is to only write to the SQL database. Then consume the changelog of the database and update any dependent data stores. I call this approach database stream writer. This idea comes from a series of blog posts Martin Kleppmann did on Events and Stream Processing. With this system you can continue writing to the existing SQL database but your primary application no longer has to deal with updating dependent data stores.
How do we implement the database stream writer pattern?
This pattern is implemented by turning Change Data Capture on for your database. Change Data Capture exposes the changes made to a database to a third party application based on its commit log. Many database vendors support this feature, for example, postgresql exposes a method called logical decoding that can be used to parse updates from the write ahead log. SQL Server calls this feature change data capture where updates to tables are stored in system tables inside the same database and exposed via table functions. SQL Server also has a lighter weight feature called change tracking that does not track individual column updates but simply tracks when a table row is modified. For many applications just knowing that a row changed is enough information to make necessary updates to dependent data stores (like invalidating a cache).
With a change data capture system in place, the last step is to write an application to consume the change data capture stream and write the data to downstream systems. In my next post, I will detail how to implement a system like this using SQL Server’s Change Tracking and a C# application for consuming the change stream.